Grid Basics
Concepts
One of Platform's most powerful features is its Computational Grid, or simply referred to as the Grid. This feature allows a developer to break down a larger task into smaller, potentially interdependent tasks to be executed asynchronously in as parallel a fashion as possible. This allows one to increase throughput for a large category of algorithms by adding additional grid nodes to handle the parallel tasks.
In its simplest form, the Grid allows you to run asynchronous tasks based on real-time requests or schedule based workflows. There are a number of features that make the Grid superior to simple schedule based execution common to most operating systems:
Task Retries - each task will be retried up to a configurable limit until it succeeds.
Dependencies - each task may depend on other tasks and will not execute until those pre-requisite tasks have completed successfully
Time Limits - sets the maximum amount of time the task is allowed to execute before the scheduler kills the task's threads.
Distributed Parallel Execution - each type of task has a configurable number of threads per node. The more nodes you configure, the faster the overall throughput. Furthermore, each task can run on any nodes that have been configured giving you automatic fail-over, redundancy, and a measure of load-balancing.
The Computational Grid is especially useful for processes that can be split into discrete tasks. By splitting a process into tasks, you have the flexibility of running each task in parallel, with the grid handling any retries and failures. If the process is partially sequential, you can configure the dependencies such that the process can continue when dependencies are satisfied or fail-fast when a dependency fails. These features make the Computational Grid useful when interacting with external systems that may not be 100% reliable. If an error occurs during the execution of a task, the grid can retry the task until it runs out of retries or succeeds.
To work with the Grid, you need to write Java code using several classes provided by the One Network Platform. The Grid's execution is controlled using an XML file. The remainder of this chapter discusses the elemental classes need to place operational tasks on the Grid.
GridTask
A GridTask is a unit of execution for the grid. Each GridTask has a single task type and will be run by one TaskPerformer.
Tip
See the "Configuration" section and the GridTask javadoc for more details on the specifics of these classes.
GridTasks have a well-defined life-cycle. Consider the following flow chart that might represent the life-cycle of any given task.
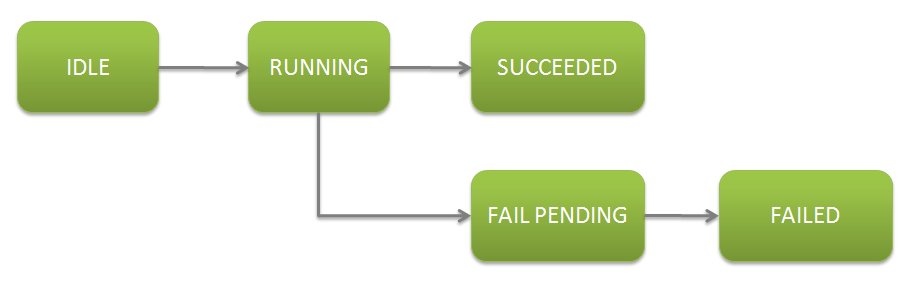
GridTasks are executed by TaskPerformers. When they are executed, GridTasks have a status and a result. The status tells you what is happening within the TaskPerformer. The result tells you what happened when the status last changed. The possible values for the status and the result are available as static variables.
In the above example, a GridTask will go from a status of IDLE to a status of RUNNING when it starts. If something goes wrong during the execution of the task, the TaskPerformer returns either TaskResult.RETRY or TaskResult.FAIL depending on whether or not the task is configured to retry and if it is, then depending on whether or the number of retries has not exceeded the set limit.
If the task performer returns the result TaskResult.RETRY, and the task has retries left, it will move back to the IDLE state so that the task gets tried again. If the task is not set to retry, or has reached the limit on the number of retries allowed, the task moves to FAIL PENDING, after which an administrative task will move the task to FAILED. The GridTask will only move from RUNNING to SUCCEEDED when the TaskPerformer returns TaskResult.SUCCEED.
A GridTask may stall during execution if it runs for a longer period of time than its configured allotment. The thread running the TaskPerformer will be interrupted and forcibly killed when this occurs and the task will be retried if possible.
GridJob
A GridJob is simply a collection of related GridTasks. Any parameters set on the job will be passed on to the task once the task is added to the job.
Like the GridTask, GridJobs also have a well-defined life-cycle. As shown below, a GridJob can be in one of: IDLE, RUNNING, SUCCEEDED, or FAILED.
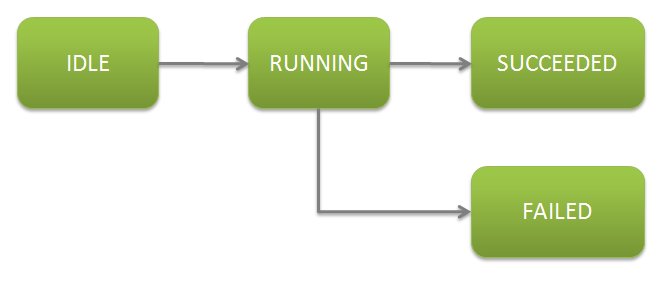
A job holds a status of IDLE if none of its tasks have begun executing and a status of SUCCEEDED only if all its tasks have completed. While its component tasks are executing, its status is RUNNING. If any of its requisite component tasks fail, the status becomes FAILED.
TaskPerformer
A TaskPerformer is a stateless class that handles the execution of a task. Remember, it's not the TaskPerformer that has a state, it's the GridTask itself. The TaskPerformer simply executes the task. Each TaskPerformer has a unique type that corresponds to the task type on a GridTask.
Dependencies
A GridTask may depend on a GridJob, another GridTask, or both and will only start once its dependencies have completed successfully. A task designed to be a pre-requisite to other tasks can be set to propagate its failure status to dependent tasks. This means a GridTask can fail without ever executing if one of its dependencies has the propagate fail flag set and that dependency fails.