Model-based
A Model-based processor uses SPT actions to persist the data from the inbound interface to the database.
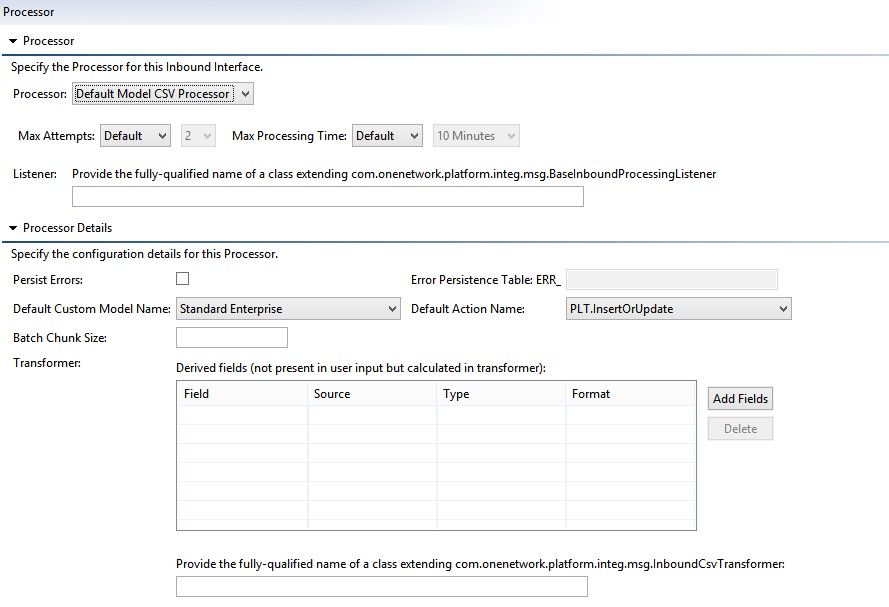
This processor is configured as follows:
Max Attempts – defines the maximum number of attempts Platform will make to process a message for this interface. The default is 2. If an attempt fails for any reason (a database connection is interrupted, the server is shut down, etc), it will retry until this max is exceeded.
Max Processing Time – the maximum amount of time allowed for processing a single attempt. Thus if you want to be sure that no single Order file takes longer than 20 minutes total to run before going to the next message in the queue, you might configure it with a max attempts of 2 at 10 minutes per attempt. Note that this time is approximate (the server may go a minute or two beyond the max before proceeding to the next message).
Persist Errors/Error Persistent Table – these are covered in the topic titled Error Review
Default Custom Model Name – Custom Model Name to be used when processing this interface. Please note that this is a required field when processing MessageQueue-based Messages. (For interfaces using only UI Uploads, this value can be omitted as it is provided in the UI Meta Model.)
If you add a UDF field to an interface, Default Custom Model Name field will be disabled as UDF fields are tightly coupled with custom model names.
Default Action Name – if action name is not provided in the interface, the action name must be provided here. (Again, for interfaces using only UI Uploads, this value can be omitted as it is provided in the UI Meta Model.)
If you add a Transient field to an interface, Default Action Name field will be disabled as Transient fields are tightly coupled with action.
Batch Chunk Size – normally, each incoming CSV will be split into chunks of size 50 for processing (this is configurable via the InstanceConfig.xml for the Platform instance). You can increase this value to improve performance, at the expense of possibly failing a larger group of transactions if the DB transaction is rolled back.
Derived Fields – any field which you want to write to the database but which the user didn't explicitly provide must be given here. If you implement an InboundCsvTransformer, the CsvRow objects given to it will include all user-provided columns, plus empty strings for all of the DerivedField columns to allow you to set them.
Transformer – By extending a class, you can implement a custom Transformer to set default values, convert values from one format to another, etc.
It also has the following limitations:
Only fields from a single ModelType (child levels are OK) are allowed in the interface. Custom fields are also allowed, but they will only be used for the purposes of the transformer; they are not persisted directly.
The Model-Based CSV Processor uses the BatchWrite family of grid tasks to execute the write. For this reason, you will need to ensure you have configured dvce-app-config properly on nodes that will participate in the processing of these messages. You should have at a minimum one InitiateBatchWriteTaskPerformer, one BatchWriteSingleRelationalChunkTaskPerformer and one CompleteBatchWriteTaskPerformer. These numbers should be increased to handle multiple types of models concurrently, and BatchWriteSingleRelationalChunk should be further increased if you plan to use Parallel Processing within an interface.