Working with the Standard Process Template (SPT)
When you build a module, you should design the major functionality within the Module Process Template (MPT). If there is only one multi-party community ("Value Chain") for which you've deployed the module, this will suffice. However, if you need to accommodate a second community with differing business requirements, the Standard Process Template (SPT) allows you to make those variations.
For example, let's assume you deployed your Bookstore module as an instance to be used by retail book publishers and their suppliers. But later, you want to cater to another audience: educational textbook publishers and suppliers. If the business processes are the same between retail and education, you can simply onboard those companies onto your existing instance. But what if they're different? For example, educational books may require additional government approval processes and funding. It would be ideal if we could reuse the base Bookstore module but deploy a "variation" on top of that to cover the differences between retail and educational scenarios.
To handle cases where we want to deploy multiple "communities" with different business processes on top of the same underlying set of modules, we provide two concepts: the Value Chain and the SPT.
The Value Chain is a complete end-to-end representation of a supply chain. You will notice that all models created in the SDK have a Value Chain ID; this allows multiple Value Chains to live side-by-side in the same database without any collisions. Each multi-party network corresponds to a Value Chain.
The SPT is a Value Chain-specific module. In most ways, it is similar to a module - it allows you to create actions, views, state machines, reports and other artifacts. The primary difference is, while all module actions/views/etc apply to all Value Chains, the SPT is scoped to just a single Value Chain. That means the processes covered by the SPT are isolated to just one multi-party network.
By having different Value Chains with different SPTs, we can give a different experience to different users:
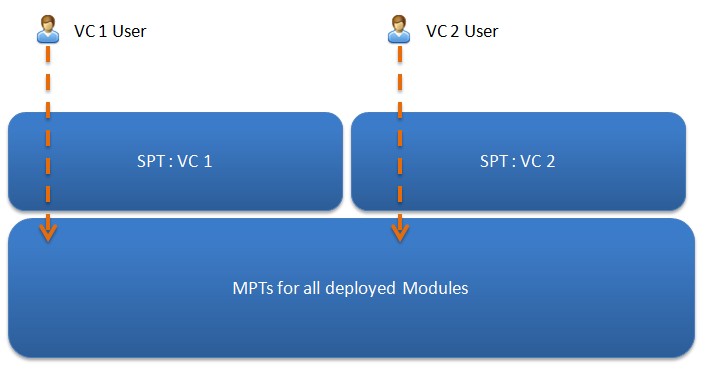
Every part of the multi-party process is managed through the SPT. Thus when a user is presented with menus, or gets a list of actions, or views a report, the system will check in the SPT for the User's Value Chain first, then return anything from the MPTs for the modules currently deployed.
For the most part, you'll find a lot of the same constructs in the SPT that you find in the MPT. You can create workflows, state machines, etc. Generally, you should create elements you want to customize in the SPT, while major functionality should be implemented in the MPT. Since the objective is to allow you to customize a module for a particular network, the SPT editor is designed to make these customizations quickly.
Another advantage you have in the SPT, since its in the dataset, is server restarts are not required to review your changes. The SPT is loaded dynamically, so each time you run the Ant load-data script or publish the SPT using the "Submit to Server" button in Studio, you are building and loading up your changes to the SPT.
Since many things are the same as they are in the MPT, this section will focus primarily on the differences.